
Иногда в поисковой выдаче можно наблюдать очень интересные результаты. Например, вот такие:
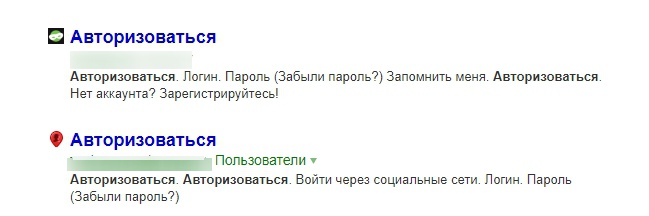
Это так называемые «мусорные страницы», которые нужно закрывать от индексации.
Как сделать так, чтобы в результаты поиска не попадали те страницы, которых там быть не должно? Для этого нужно настроить файл robots.txt.
Файл robots.txt – это инструкция для поисковых роботов. Он содержит рекомендации, какие страницы можно индексировать, какие – нельзя. С помощью этого файла можно запретить индексацию сайта или отдельных страниц.
Однако, когда проводишь аудит сайтов, у которых как раз проблемы с индексацией, то самая первая проблема, которую видишь – это как раз отсутствие данного файла.
Это не проблема вселенского масштаба, конечно, но, если этого файла у вас на сайте нет, то:
— индексация может пройти некорректно;
— сайт будет долго заходить в индекс;
— в результаты поиска могут попасть мусорные страницы или те, индексация которых нежелательна (личные данные пользователей, вход в админку и т.п.).
Обратите внимание, что в данном файле содержатся именно рекомендации, а не команды поисковым роботам. Иногда робот может игнорировать ваши команды, и все равно выхватить в индекс те страницы, которые вы запретили к индексации – особенно, если на них ссылаются с каких-то других страниц вашего сайта или есть ссылки с других сайтов.
Вот пример:
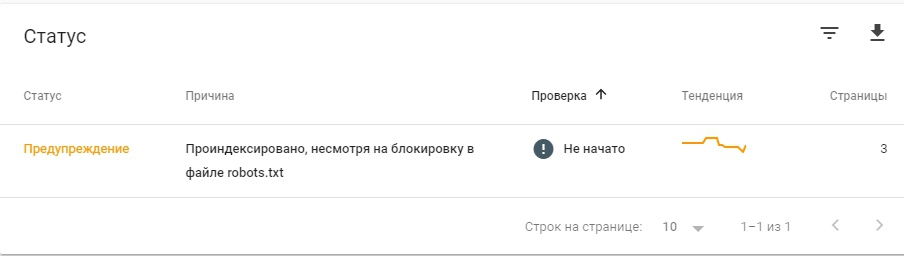
Google Search Console сразу предупреждает об этой проблеме. На некоторые страницы сайта стоит запрет к индексации, но робот все равно проиндексировал их. Нужно искать причину, и устранять проблему, если действительно эти страницы в индексе вам не нужны.
С помощью данного файла можно запретить индексацию сайта конкретной поисковой системе, или вообще запретить индексацию (и в некоторых случаях это нужно, ниже разберем, почему).
Настройка файла robots txt – это один из главных пунктов внутренней оптимизации сайта. Именно правильная настройка файла поможет сделать так, чтобы ваш сайт зашел в индекс так, как нужно.
Давайте разберемся, что это за файл, и как правильно его настроить.

Структура и местонахождение файла
Находится файл robots.txt в корневой папке сайта. Это обычный текстовый документ, и написать его можно просто в блокноте. Проверьте, есть ли он на вашем сайте: вбейте в адресную строку браузера адрес вашего сайта, и добавив через слэш robots.txt: site.ru/robots.txt.
Вам откроется что-то типа такого:
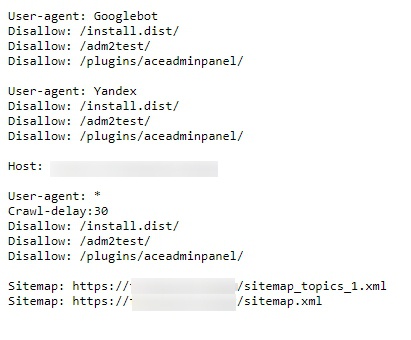
Как видите, у файла есть своя четкая структура:
— первый блок – набор команд для поискового робота от Google (Googlebot);
— второй блок – набор команд для поискового паука Яндекса;
— указано главное зеркало – Host;
— в третьем блоке рекомендации для всех поисковых роботов;
— ссылка на карту сайта.
Нет разницы, каким образом расположить данные блоки. Но правильная, «академичная» структура файла такова:
Общие правила:
User-agent: *
Потом инструкции для одного поискового робота (Яндекс), которые задаются командой:
User-agent: Yandex
затем – для другого (Google):
User-agent: Googlebot
После инструкций идет команда Host: site.ru.ру. Тут вы можете указать, какое зеркало вашего сайта главное – с www или без.
Затем указаны ссылки на карту сайта:
Sitemap: site.ru/sitemap.xml
Правила (директивы) для поисковых роботов
Команды (директивы) в файле имеют свое значение, которое понимают поисковые роботы. Самые часто используемые:
User-agent – указывает, для какой поисковой системы данная инструкция.
Disallow – запрет на индексацию. Например, командой
Disallow: /my-account
Можно закрыть на сайте от индексации личные аккаунты пользователей с их персональными данными.
Allow – открывает страницы для индексации. Но обычно эту команду не используют, робот выхватит на сайте все, что вы не закрыли.
*- любое значение.
$ — конец строки.
Порядок расположения директив на индексацию сайта не влияет. То есть, вы можете расположить блоки команд любым образом.
Как правильно настроить robots txt
Давайте попробуем правильно настроить robots txt.
Вообще этим должен заниматься ваш вебмастер. Каждый уважающий себя разработчик сайтов знает, что этот файл должен быть на сайте, и знает, как его написать. Дело 20 минут.
Но если вы занимаетесь разработкой и продвижением сайта самостоятельно, или хотите проконтролировать подрядчика – читайте дальше.
Вы можете прописать инструкцию просто в текстовом редакторе, даже в «Блокноте», который есть на любом компьютере. Общую схему документа вы уже поняли.
Обратите внимание, что после каждого блока нужно сделать пустую строку. А вот внутри пары User-agent+ Disallow пустых строк быть не должно
User-agent: *
Disallow: /cart
User-agent: YandexDisallow: /cart
Данными командами мы закрыли от индексации страницу корзины. Обратите внимание, что адреса страниц должны быть относительными, то есть не нужно писать полностью адрес сайта, а только то, что находится после основного адреса: / и название страницы.
Например, если бы мы хотели закрыть в нашем журнале от индексации раздел с новостями.
User-agent: Googlebot
Disallow: /blog/novosti/
То есть, слэш (/) и то, что идет после него, а https://freelance.today не пишем. Это и называется «относительный адрес».
Несколько фокусов с настройкойrobots txt
Сейчас рассмотрим некоторые команды, с помощью которых вы можете провести интересные манипуляции с сайтом.
Например, полностью закрыть сайт от индексации в robots txt можно следующим образом:
User-agent: *
Disallow: /
Если ваш сайт никак не зайдет в индекс – проверьте, может у вас в файле robots txt как раз есть такая команда. Иногда разработчики могут просто забыть убрать ее после запуска сайта.
Также вы можете закрыть от индексации конкретные страницы:
User-agent: Yandex
Disallow: /this-page.html
Можно закрыть от индексации отдельный тип файлов:
User-agent: *
Disallow: /*.xls$
Например, если вы храните на сайте отчеты, которые не должны видеть посторонние.
Есть фокус и с картой сайта. Иногда Яндекс Вебмастер может указывать на ошибку, если вы часто публикуете новые посты, или добавили раздел, а в карту его не внесли. Если вы постоянно публикуете новый уникальный контент, в файл robots txt можете ссылку на него не добавлять.
Как добавить файл на сайт?
После того, как вы написали этот файл, его нужно залить в корневую папку сайта. Подключитесь по FTP и просто залейте файл, как любые остальные.
Потом нужно будет проверить корректность этого файла. В этом помогут инструменты для вебмастеров.
Например, Яндекс.Вебмастер (Инструменты – Анализ robots.txt) и Google Search Console (Сканирование — Инструмент проверки файла robots.txt.).
Что нужно закрыть от индексации?
«А зачем вообще что-либо закрывать?», — скажете вы. Да, может показаться, что чем больше страниц в индексе, тем лучше. Но еще в самом начале статьи я показала, какие страницы не должны быть в индексе – они бесполезны. Это просто мусор.
В индекс должны попадать те страницы, придя на которые, посетитель получит пользу от вашего сайта, или совершит целевое действие. То есть, первым делом это должны быть посадочные страницы, страницы товаров и услуг, страницы категорий, статьи блога. А вот все, что приведено в списке, нужно от индексации закрыть:
— административную панель сайта;
— страницы или файлы с личными данными;
— страницы входа;
— корзину;
— страницы регистрации;
— дубли страниц;
— сайт, который находится в процессе разработки на отдельном хостинге. Чтобы он не зашел в индекс раньше времени, или чтобы не создавать дубли, рабочую версию нужно закрыть от индексации полностью.
Вы можете легко закрыть от индексации любую страницу на сайте, появление которой в результатах поиска будет для вас нежелательным – как, я уже показала.
Следите за возможными проблемами с файлом через инструменты для веб-мастеров. Это не сложно – Google сразу оповестит вас об ошибках уведомлением на почту, так же как и Яндекс.
Высоких вам позиций!
0 комментариев